In the last two parts we did some customer analysis and prepared our data. Now we’re going to cluster our data by k-means algorithm and hopefully enable some business insights!
How to evaluate the number of cluster?
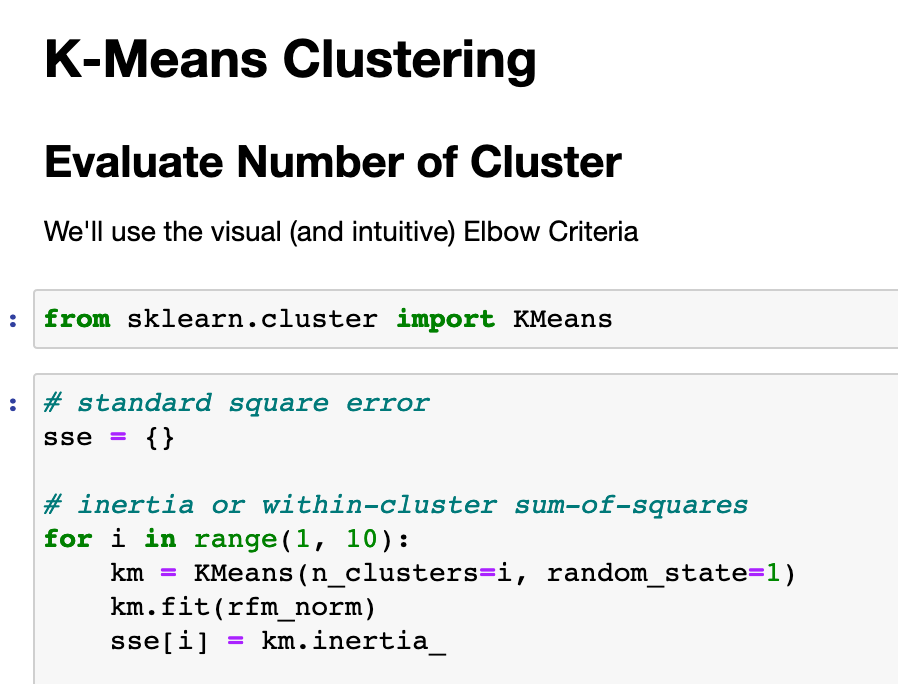
In the first step we’ve to find out how many clusters are in our data. Therefore we can use several methods. A mathematical approach is the Silhouette analysis. For our example we’ll use the heuristic Elbow method.
from sklearn.cluster import KMeans
# standard square error
sse = {}
# inertia or within-cluster sum-of-squares
for i in range(1, 10):
km = KMeans(n_clusters=i, random_state=1)
km.fit(rfm_norm)
sse[i] = km.inertia_
plt.title("Elbow n cluster")
sns.pointplot(x=list(sse.keys()), y=list(sse.values()))
plt.show()
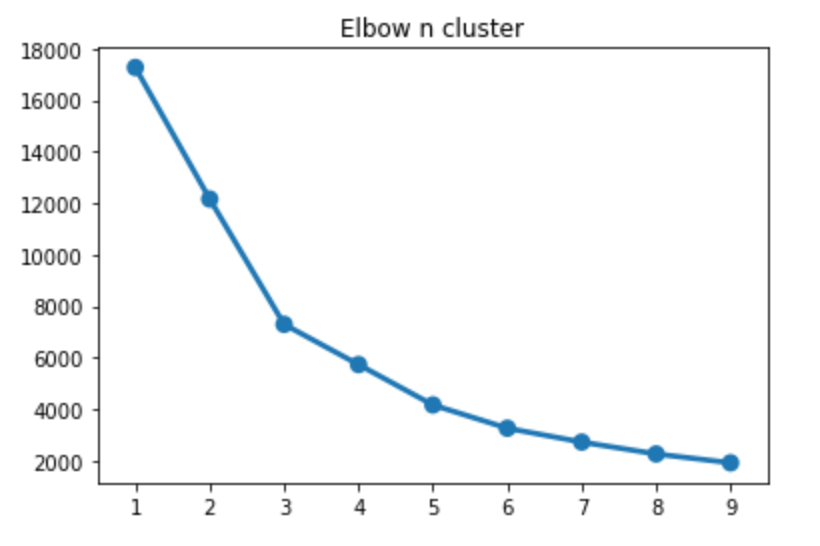
The number of cluster is determined by „the elbow“ – is everyone fine with 3?
K-means clustering
Anyway we’re going to check this indication.
- we need the labels (Cluster 1, Cluster 2…) for our data
# get the labels from the clustering
def get_labels(nlabels):
km = KMeans(n_clusters=nlabels, random_state=1)
km.fit(rfm_norm)
labels = km.labels_
return labels
- we use the cluster to group the customer data and calculate the averages for your values
# DRY - don't repeat yourself ;-)
def cluster_data(org_data, n_cluster):
clust_label = get_labels(n_cluster)
cluster_df = org_data.assign(Cluster = clust_label)
return cluster_df.groupby(['Cluster']).agg({
'Recency':'mean',
'Frequency':'mean',
'MonetaryValue':['mean', 'count']
}).round(0)
Now we can easily check our assumptions and discuss with team mates and business experts, if the clustering makes sense – for e.g. the next marketing campaigns.
# check 2-4 cluster
for i in range(2,5):
cluster = cluster_data(rfm_data, i)
print(cluster)
print()

Conclusion
In the last two sessions we did some customer analysis and prepared our data. Now we’re going to cluster our data by k-means algorithm and receive some business insights!
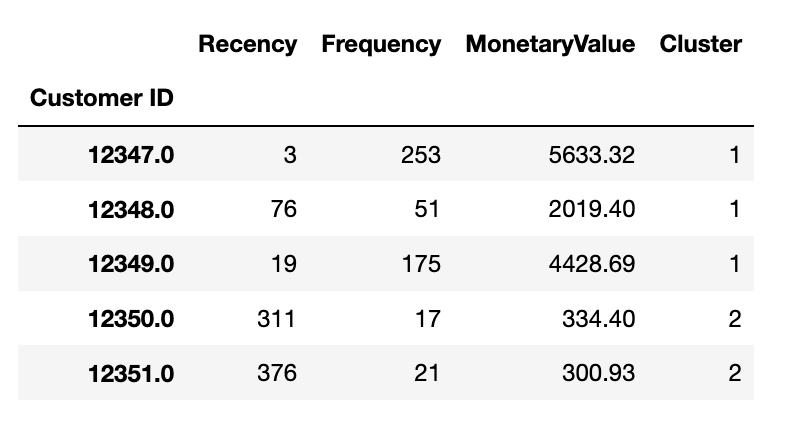
# add cluster label to customer data
cluster_label = get_labels(3)
rfm_data = rfm_data.assign(Cluster = cluster_label)
rfm_data.head()